
5 Medias
What is CanaryPDF?
CanaryPDF is a free, all-in-one PDF toolkit to extract tables, pull images, and edit pages securely in your browser. No file uploads, no sign-ups, and no limits. Just the tools you need to get your work done privately.
Core Features
- Extract Tables to CSV & JSON
- Extract High-Quality Images
- Rotate
- Delete & Reorder Pages
- Merge PDFs
- Installable Offline-Capable App for Desktop & Mobile
Pricing Model
Ideal For
Content Writers
Agencies
Students
Designers
Small Businesses
Teachers
Coaches & Mentors
Marketers
Influencers
Social Media Managers
Bloggers
Sales Teams
Project Managers
Event Planners
Consultants
Nonprofits
Legal Professionals
Accountants
Use CanaryPDF as an Alternative to
Detailed Description
Dealing with PDFs can be a pain, especially when you need to get data out or make simple edits. Most online tools force you to upload your sensitive files, creating major privacy risks and leaving your data exposed.
CanaryPDF changes that.
It's a suite of powerful, 100% free PDF tools that run entirely in your browser. Your files are never uploaded to a server, ensuring your data remains completely private and secure on your own computer.
What you can do with CanaryPDF:
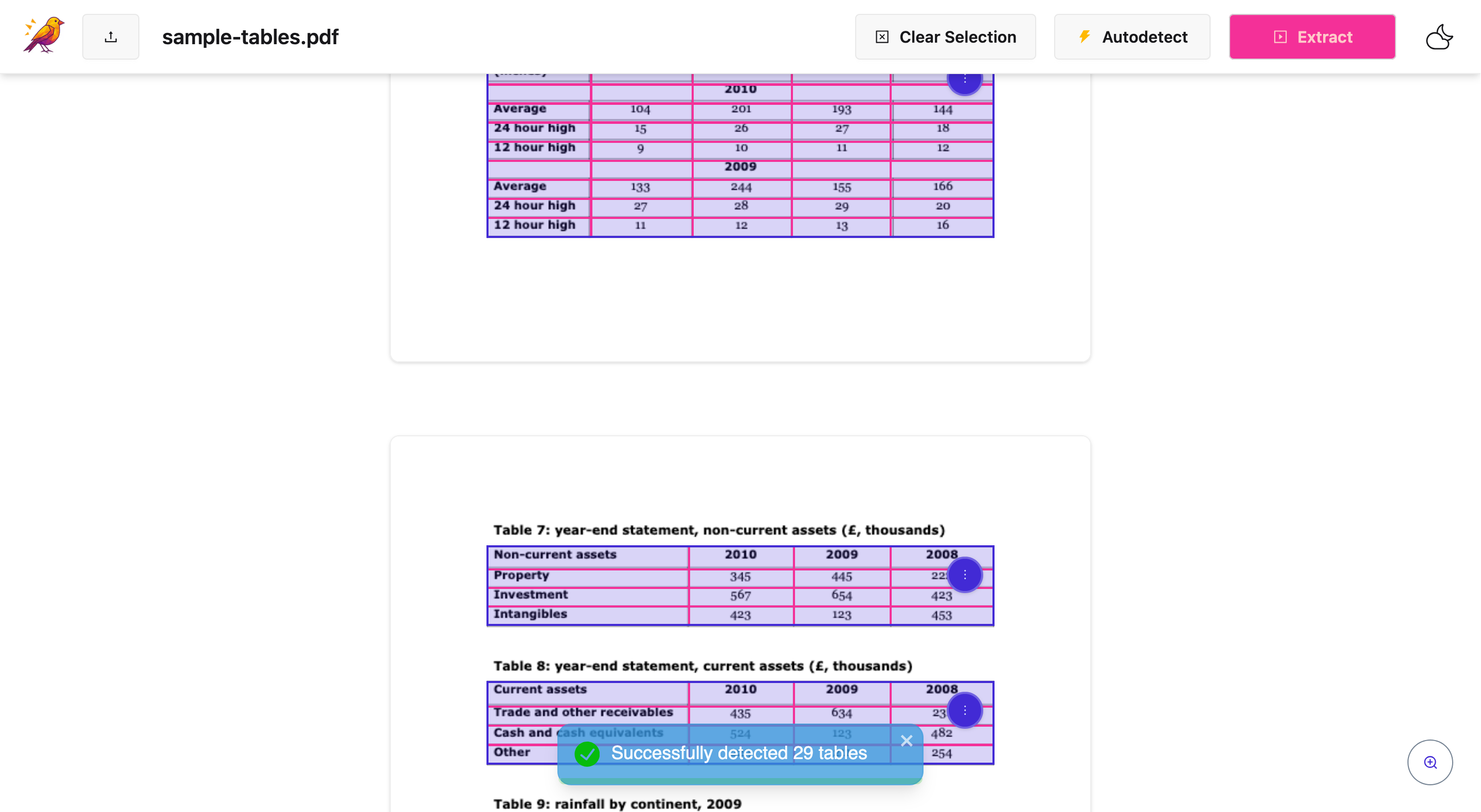
- 📄 Extract Tables: Automatically detect and pull tabular data from any PDF. Export to CSV (for Excel) or JSON in a single click.
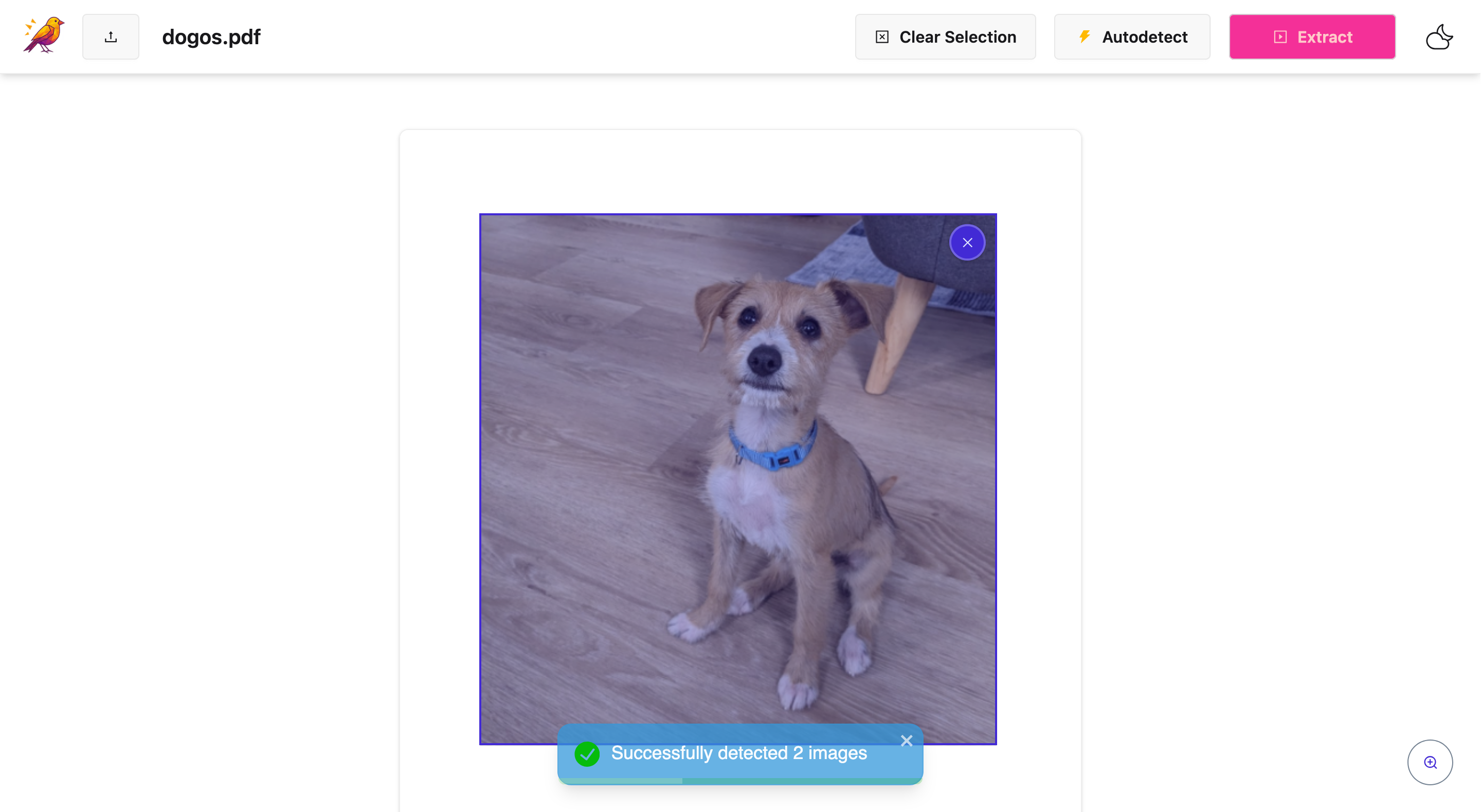
- 🖼️ Extract Images: Pull every image from a PDF and save them as high-quality PNG, JPEG or WebP files.
- ✂️ Edit Pages: Easily merge multiple PDFs, rotate, reorder or delete unwanted pages.
- More features coming soon.
There are no sign-ups, no ads and no limits. Just simple, powerful PDF tools that respect your privacy.
CanaryPDF Reviews
No reviews yet.

AMA with Maker (6)
I love that you say it's private, but how can I be sure my PDFs aren't being stored on some server somewhere when I use the edit feature?
CanaryPDF uses WebAssembly that runs entirely in your browser's memory. When you edit a PDF: 1. Your file is read into browser memory (never sent anywhere) 2. It is processed locally using your device's CPU 3. The edited PDF is generated in memory and saved directly to your device 4. Once you close the tab, the memory is cleared - nothing persists You can verify: - Check Network tab - no file uploads - Disconnect your internet after loading the page (before opening your PDF) - editing still works Your PDFs never leave your device. That's the point - the privacy is by design, not just by policy.
My boss needs me to pull all the charts from a huge report ASAP, and I'm worried about quality. If I use CanaryPDF to extract the images, will they stay high-res and not get all pixelated or compressed?
Yes, images stay high-resolution. Here's how it works. CanaryPDF uses two methods to preserve quality. First, raw extraction (preferred): when possible, CanaryPDF extracts images directly from the PDF's original data streams, which preserves the exact quality embedded in the PDF with no compression and no quality loss. Second, high-DPI fallback: if raw extraction isn't possible (which is rare), we use 600 DPI screenshots, which is more than enough for professional use. What you get: original quality when the PDF contains raw image data, 600 DPI screenshots as a fallback (equivalent to print quality), no compression applied since images are saved exactly as extracted, and multiple format options including PNG (lossless), JPEG, or WebP. For your use case, charts and graphs from reports typically extract at original quality, and the 600 DPI fallback ensures even complex vector graphics render crisply. Try it on a sample page first to confirm quality, then extract the full report. Your boss will get publication-ready images.
I love that you don't upload files, but how does that actually work? Is my data really never sent to your server? I'm dealing with some sensitive client contracts.
Your data is never sent to our servers. Here's the technical breakdown. CanaryPDF is a client-side application that runs entirely in your browser. We use PDF.js (Mozilla's library) to read PDFs in browser memory, QPDF-WASM (WebAssembly) to process PDFs using your device's CPU, and we have zero server processing since we don't have endpoints that accept file uploads. You can verify this by opening DevTools, going to the Network tab, filtering by "Fetch/XHR", processing a PDF (you'll see no file uploads, only page assets), or by disconnecting internet after the website loads (all features still work). Files exist only in your browser's temporary memory, processing happens on your device, edited documents are saved directly to your device, and there are no server logs, no cloud storage, and no third-party access. Why this matters: unlike services that upload files (even temporarily), CanaryPDF can't access your data because it never leaves your device. This is privacy by architecture, not just policy. Your client contracts stay on your machine, they're never uploaded anywhere.