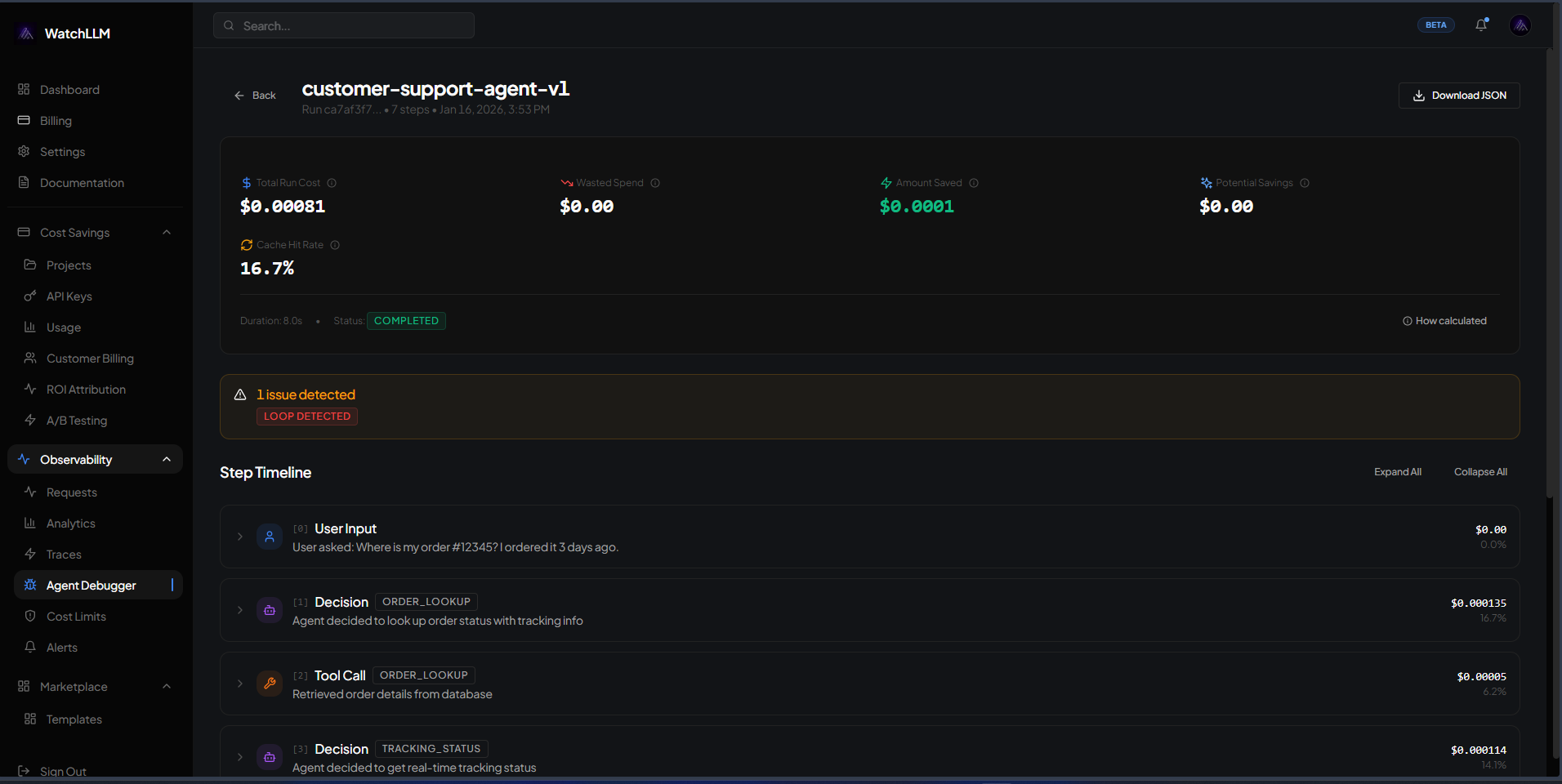
What is WatchLLM?
Core Features
- Cost Kill Switch with configurable limits
- Real-Time Alerts on Discord / Slack / User's choice
- Pass-Through Billing
- Semantic caching with vector similarity and prompt normalization
- Agent debugger with Loop detection
Pricing Model
Ideal For
Use WatchLLM as an Alternative to
Detailed Description
WatchLLM is a sophisticated AI monitoring and analytics platform designed to provide unparalleled visibility into the behavior, performance, and cost of your large language model applications. In an era where AI integration is critical but often opaque, WatchLLM serves as your comprehensive observability suite, transforming raw API logs into actionable intelligence. It empowers development teams, product managers, and business leaders to ensure reliability, optimize spending, and enhance the quality of AI-driven features with precision and ease.
Why Choose WatchLLM?
✨ **Granular Performance Tracking:** Monitor latency, token usage, and error rates for every model call across providers like OpenAI, Anthropic, and others. Identify bottlenecks and ensure consistent user experiences.
🎯 **Cost Intelligence & Optimization:** Gain crystal-clear insights into your AI expenditure. Break down costs by project, feature, user, or model to pinpoint savings opportunities and forecast budgets accurately.
🔒 **Content & Safety Monitoring:** Automatically scan prompts and completions for sensitive data, policy violations, or toxic content. Proactively manage risks and maintain compliance with customizable alerting.
📊 **Unified Analytics Dashboard:** Move beyond fragmented logs. WatchLLM aggregates all your LLM traffic into a single pane of glass with intuitive charts, filters, and drill-down capabilities for holistic analysis.
Built for engineering teams, WatchLLM integrates seamlessly into your existing workflow. With simple SDK integration or flexible pipeline ingestion, you can start monitoring in minutes without disrupting your production environment. The platform goes beyond simple dashboards, offering automated alerting for anomalies, detailed tracing of complex conversational chains, and the ability to replay and debug specific user sessions. This depth of analysis is crucial for iterating on prompt engineering, validating the impact of model changes, and ultimately building trustworthy, efficient, and cost-effective AI products.
Transform your LLM operations from a black box into a strategic asset with detailed observability.
Explore the features of WatchLLM and start your free trial today.

AMA with Maker (0)